Daten integrieren
Um Ihre Daten in Cognite Data Fusion (CDF) zu analysieren und zu kontextualisieren, müssen Sie effiziente Datenintegrations-Pipelines zwischen Ihrer vorhandenen Dateninfrastruktur und dem CDF-Datenmodell aufbauen.
In CDF enthält eine Datenintegrations-Pipeline in der Regel Schritte zum Extrahieren, Transformieren und Kontextualisieren von Daten. In dieser Einheit werden diese Schritte im Einzelnen vorgestellt.
Für die Integration von Daten in das CDF-Datenmodell können Sie Standardprotokolle und -schnittstellen wie PostgreSQL und OPC-UA sowie Extraktions- und Transformationstools von Cognite oder Drittanbietern verwenden. Die Tools sind von entscheidender Bedeutung für Ihre Datenvorgänge. Wir empfehlen, ein modulares Design für Ihre Datenintegrations-Pipelines zu verwenden, um ihre Verwaltung so weit wie möglich zu vereinfachen.
Daten extrahieren
Die Extraktionstools werden mit den Quellsystemen verbunden und übertragen Daten in ihrem ursprünglichen Format an den Bereitstellungsbereich. Datenextraktoren können in verschiedenen Modi ausgeführt werden. Sie können Daten streamen oder in Batches in den Bereitstellungsbereich extrahieren. Außerdem können sie Daten mit nur wenig oder gar keiner Datentransformation direkt in das CDF-Datenmodell extrahieren.
Mit Lesezugriff auf die Datenquellen können Sie die Systemintegration so einrichten, dass Daten in den CDF-Bereitstellungsbereich (RAW) gestreamt werden. Dort können Daten normalisiert und angereichert werden. Wir unterstützen Standardprotokolle und -schnittstellen wie PostgreSQL und OPC-UA, um die Datenintegration mit Ihren vorhandenen ETL-Tools und Data-Warehouse-Lösungen zu erleichtern.
Wir bieten zudem speziell angefertigte Extraktoren für branchenspezifische Systeme und gebrauchsfertige Standard-ETL-Tools für herkömmliche tabellarische Daten in SQL-kompatiblen Datenbanken.
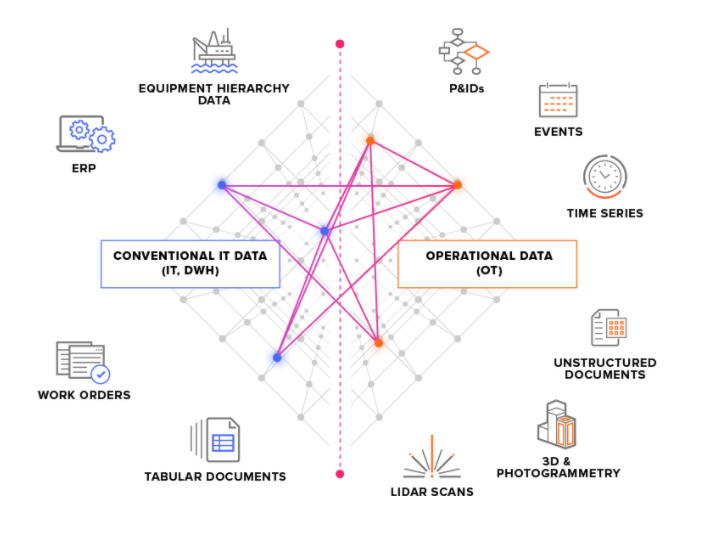
Wir unterscheiden bei Quellsystemen zwischen zwei Haupttypen:
-
OT-Quellsysteme: Zum Beispiel industrielle Kontrollsysteme mit Zeitreihendaten. Die Übertragung von OT-Daten an CDF kann zeitkritisch sein (wenige Sekunden), und oft müssen die Daten kontinuierlich extrahiert werden.
-
IT-Quellsysteme: Zum Beispiel ERP-Systeme, Dateiserver, Datenbanken und Engineering-Systeme (3D-CAD-Modelle). IT-Daten ändern sich in der Regel weniger häufig (Minuten oder Stunden) als OT-Daten und können oft in Batch-Jobs extrahiert werden.
Alternativen für Bereitstellungsbereich
Daten fließen von Extraktoren in die CDF-Aufnahme-API. Ab diesem Punkt sind sie in der Cloud gespeichert. Die erste Anlaufstelle ist der CDF-Bereitstellungsbereich (RAW). Dort werden tabellarische Daten in ihrem ursprünglichen Format gespeichert. Mit diesem Ansatz können Sie die Logik in Extraktoren minimieren und Datentransformationen in der Cloud ausführen und wiederholen.
Wenn Sie Ihre Daten bereits in die Cloud streamen und dort speichern, beispielsweise in einem Data Warehouse, können Sie die Daten von dort in den CDF-Bereitstellungsbereich integrieren und mit Cognite's Tools transformieren. Alternativ dazu können Sie die Daten in Ihrer Cloud transformieren und den CDF-Bereitstellungsbereich umgehen, um die Daten direkt in das CDF-Datenmodell zu integrieren.
Daten transformieren��
Der Transformationsschritt formatiert die Daten und verschiebt sie aus dem Bereitstellungsbereich in das CDF-Datenmodell. Dieser Schritt umfasst in der Regel die meiste Datenverarbeitungslogik.
Die Datentransformation beinhaltet normalerweise mindestens einen der folgenden Schritte:
- Daten für das
CDF-Datenmodell umformatieren, beispielsweise Datenobjekte ausCDF RAWlesen und als Ereignis formatieren. - Daten mit weiteren Informationen anreichern, z. B. Daten aus anderen Quellen hinzufügen.
- Daten mit anderen Datenobjekten in Ihrer Sammlung abgleichen.
- Qualität der Daten analysieren, beispielsweise prüfen, ob alle erforderlichen Informationen im Datenobjekt vorhanden sind.
Wir empfehlen, die Daten mit Ihren vorhandenen Tools zum Extrahieren, Transformieren und Laden (ETL) zu transformieren. Sie können aber auch unser CDF Transformation-Tool als Alternative für einfache Transformationsjobs verwenden. Mit CDF Transformations können Sie Spark-SQL-Abfragen nutzen, um Daten in Ihrem Browser zu transformieren.
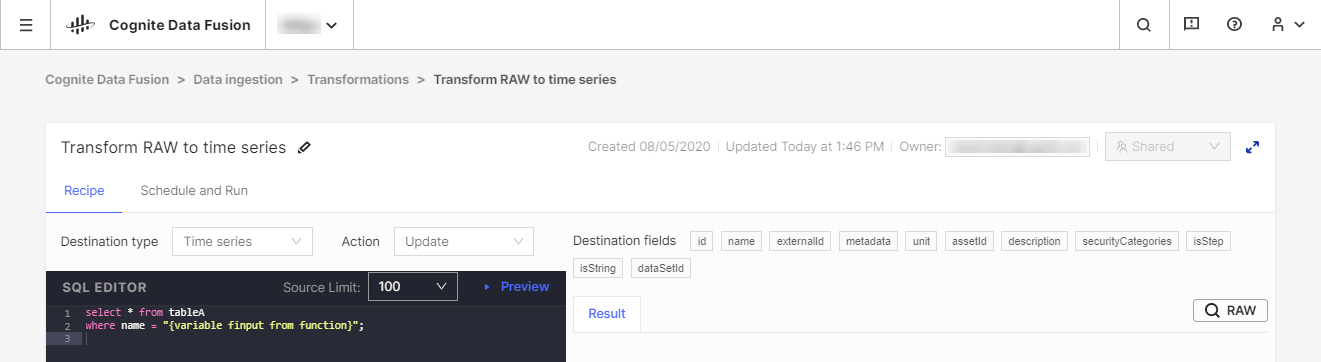
Unabhängig vom verwendeten Tool transformieren Sie Daten aus dem CDF's RAW-Speicher oder einem gleichwertigen Bereitstellungssystem in das Cognite-Datenmodell. Dort können Sie die Daten mit weiteren Beziehungen anreichern, um umfassende Analysen und Echtzeiteinblicke zu erhalten.
Daten erweitern
Ein entscheidender Bestandteil Ihrer Datenintegrations-Pipelines ist die Kontextualisierung. Dieser Prozess kombiniert maschinelles Lernen, eine leistungsstarke Regel-Engine und Fachkenntnisse, um Ressourcen aus unterschiedlichen Quellsystemen im CDF-Datenmodell einander zuzuordnen.
Im ersten Schritt der Kontextualisierung müssen Sie sicherstellen, dass jede eindeutige Einheit dieselbe ID in CDF aufweist, selbst wenn sie in den Quellsystemen andere IDs hat. Dieser Schritt wird meist während der Transformationsphase ausgeführt, wenn Sie eingehende Daten formatieren und abgleichen und mit vorhandenen Ressourcen in Ihrer Sammlung vergleichen.
Im nächsten Schritt des Kontextualisierungsprozesses verknüpfen Sie Einheiten so miteinander, wie sie in der realen Welt zueinander in Verbindung stehen. Ein Objekt in einem 3D-Modell kann beispielsweise eine ID aufweisen, die Sie einem Anlagenteil zuordnen können, während eine Zeitreihe aus einem System zur Instrumentenüberwachung eine andere ID haben kann, die Sie demselben Anlagenteil zuweisen können.
Dank der interaktiven Kontextualisierungstools in CDF kombinieren Sie maschinelles Lernen, eine leistungsstarke Regel-Engine und Fachkenntnisse, um Ressourcen aus unterschiedlichen Quellsystemen im CDF-Datenmodell einander zuzuordnen.
Beispielsweise können Sie interaktive Konstruktionszeichnungen aus statischen PDF-Quelldateien erstellen und Einheiten zuordnen, um alle Kontextualisierungs-Pipelines mit Ihrem Browser einzurichten, zu automatisieren und zu validieren, ohne dass Sie Code schreiben müssen.
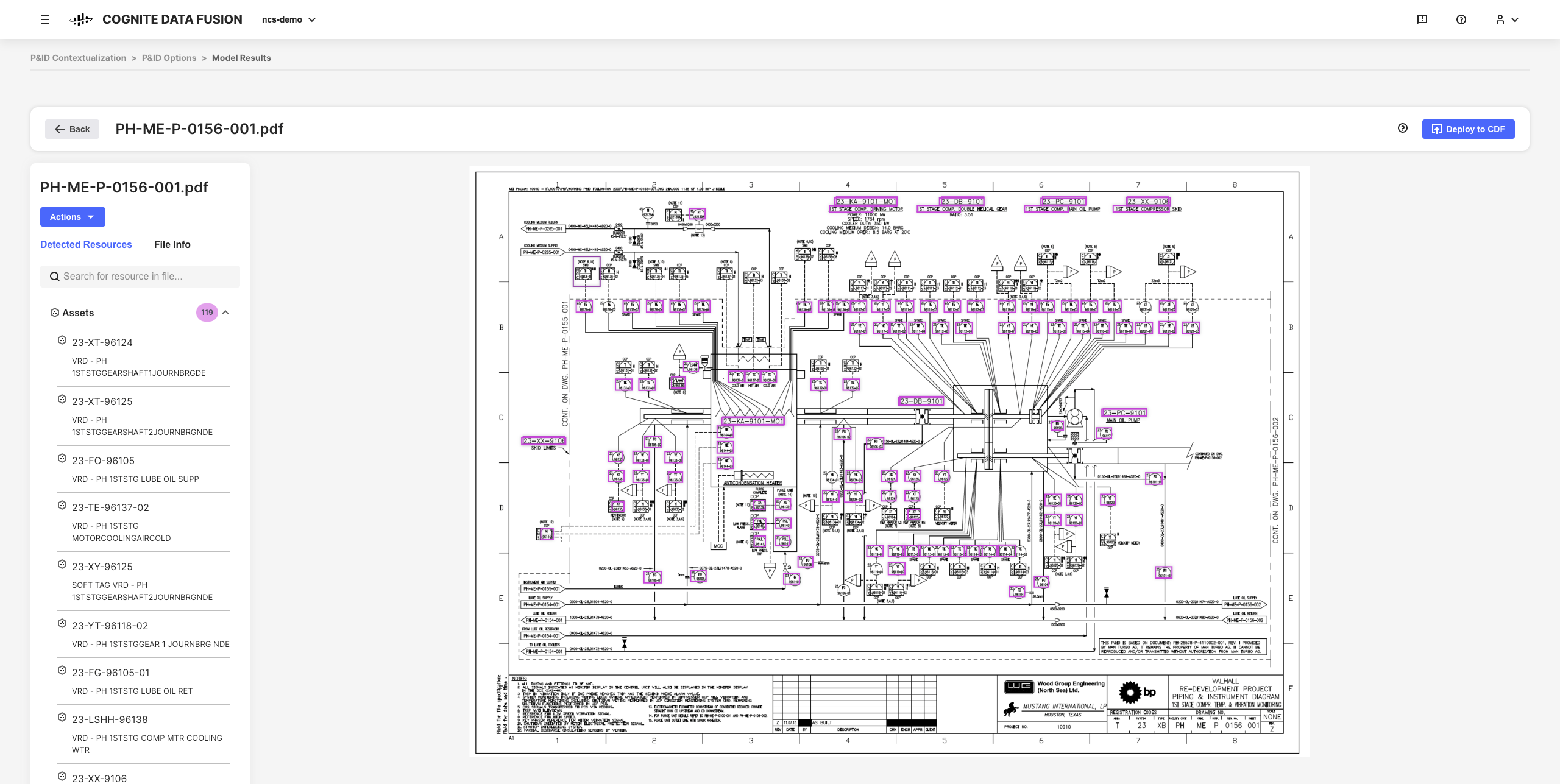
Die resultierenden verfeinerten Daten und abgeleiteten Erkenntnisse bilden die Grundlage für die Skalierung Ihrer CDF-Implementierung und -Lösungen für Ihre Organisation, während Sie Ihr Verständnis Ihrer Daten vertiefen.